
Amazon DynamoDB is a NoSQL database that is fast and flexible for any scale. I have personally been using it for more than 2 years and in this article, I am going to share with you my experience with it.

In case you are someone new to AWS then take a look at this article to know what AWS is and what solution they offer.
- Amazon DynamoDB – Overview
- Designing table
- Indexes
- Streams
- How to make it even faster
- Scan and Query Operation
- DEMO
- Conclusion
Amazon DynamoDB – Overview
According to the official AWS documentation, “Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-region, multi-active, durable database with built-in security, backup and restores, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.”
As I said Amazon DynamoDB is a NoSQL database which doesn’t mean that it is a “NO” SQL database. It means Not Only SQL database. So naturally, it does not support join. Also, keep in mind that it cannot perform aggregations such as “SUM”. NoSQL databases scale horizontally.
Designing table
The important point to remember for any NoSQL database is that we cannot join tables. So make sure you design in such a way that no joins are required. Make the document structure flat as possible. When you create a table you need to define a partition key and an optional sort key. Also, keep in mind that the maximum size of an item is 400KB.
Indexes
Indexes help you to speed up the queries. There are two indexes available in Amazon DynamoDB, they are Local Secondary index (LSI) and Global Secondary Index (GSI). LSI acts as a secondary sort key whereas GSI is more or less acts as a separate table.
Streams
Streams are something which excites me as it offers various flexibility. We can enable dynamoDb streams whenever you want to create a replica of a table or migrate the data to other databases like Elasticsearch, etc.
How to make it even faster
Amazon DynamoDB by itself is fast when partitions and sort keys are properly designed with appropriate indexes. But in some cases, we need to execute even faster queries like search engines. In those cases, you can go for Amazon Elasticsearch by enabling DynamoDB streams and handling them through AWS Lambda.
Scan and Query Operation
Whenever you want to retrieve data you will have to use either scan or query API. The scan can be used whenever you are planning to read your entire table. But make sure you are not using any filters as it will slow the process. The query can be used to get data based on some filters. If you have a GSI index created then you have to use query API in order to retrieve data.
DEMO
Open the DynamoDB console, and click on tables on the left-hand side.
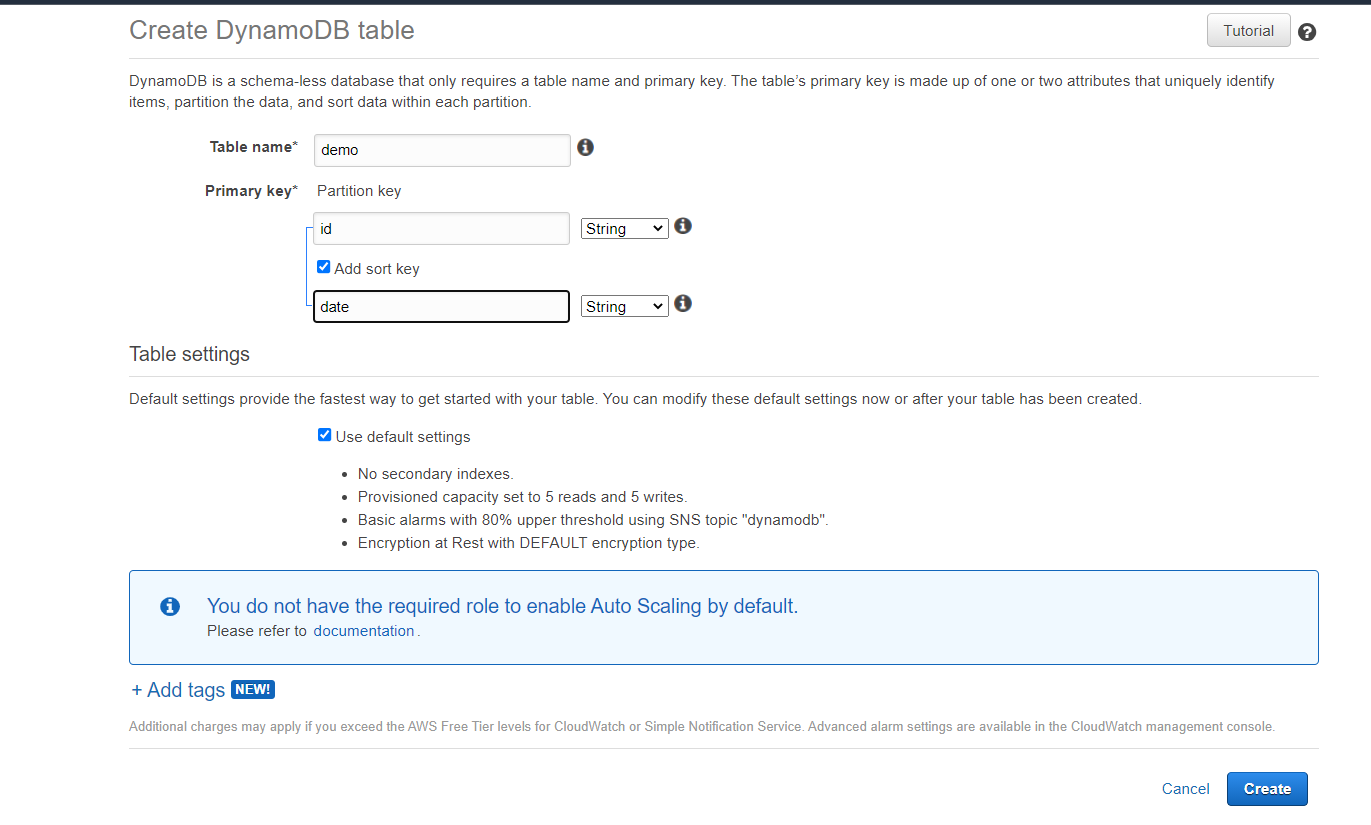
Now enter the table name, primary key, and sort key(optional), and click create. Then click on “create item” and add a record as shown below and click save.
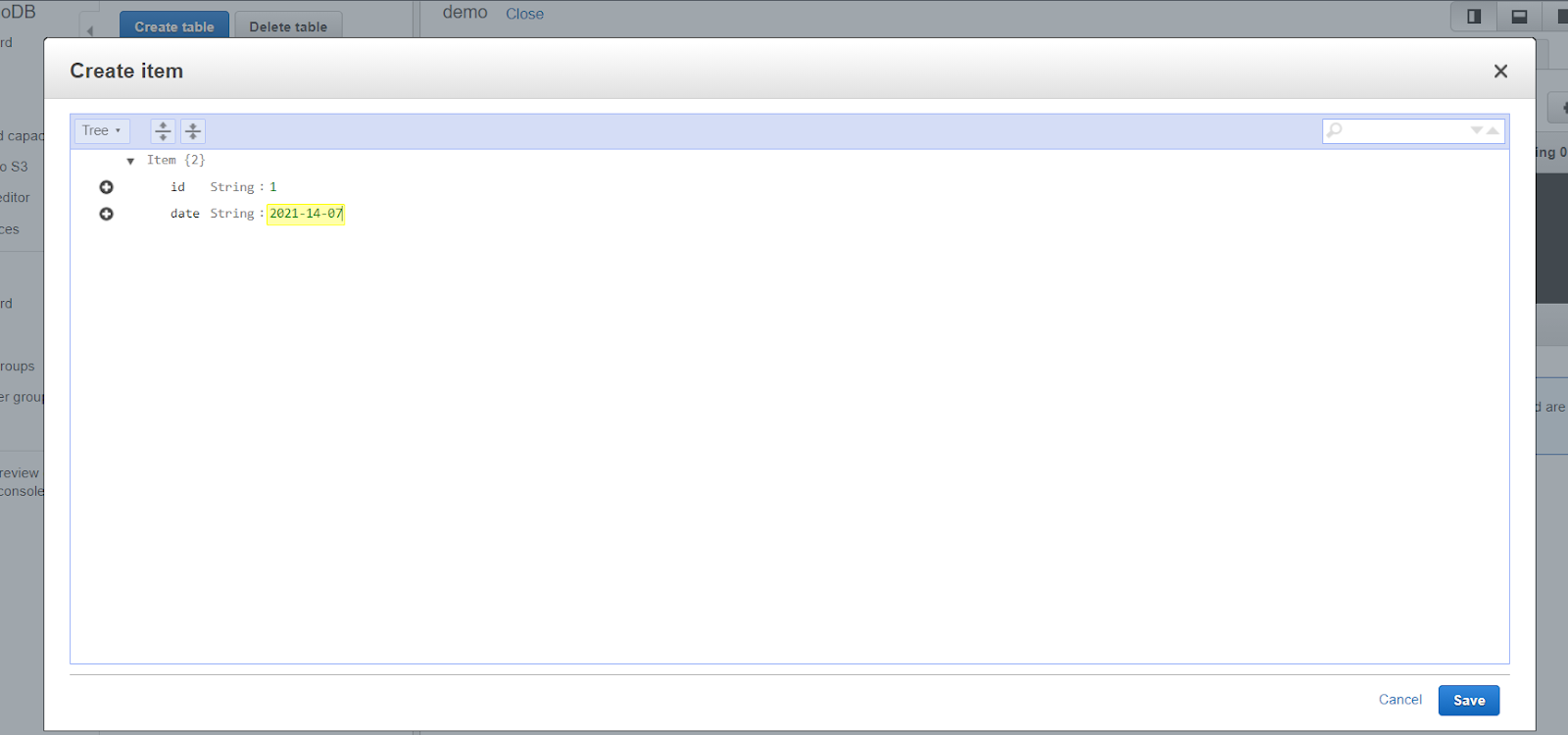
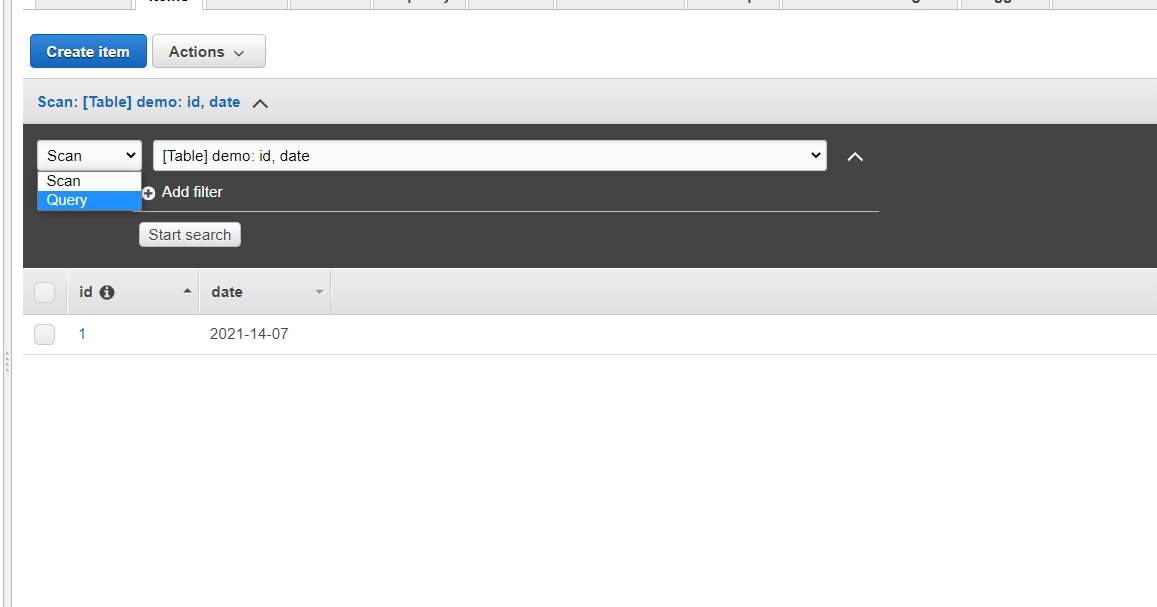
You will be able to see the data you entered. If you want to perform a query operation click on scan dropdown and select query as shown below.
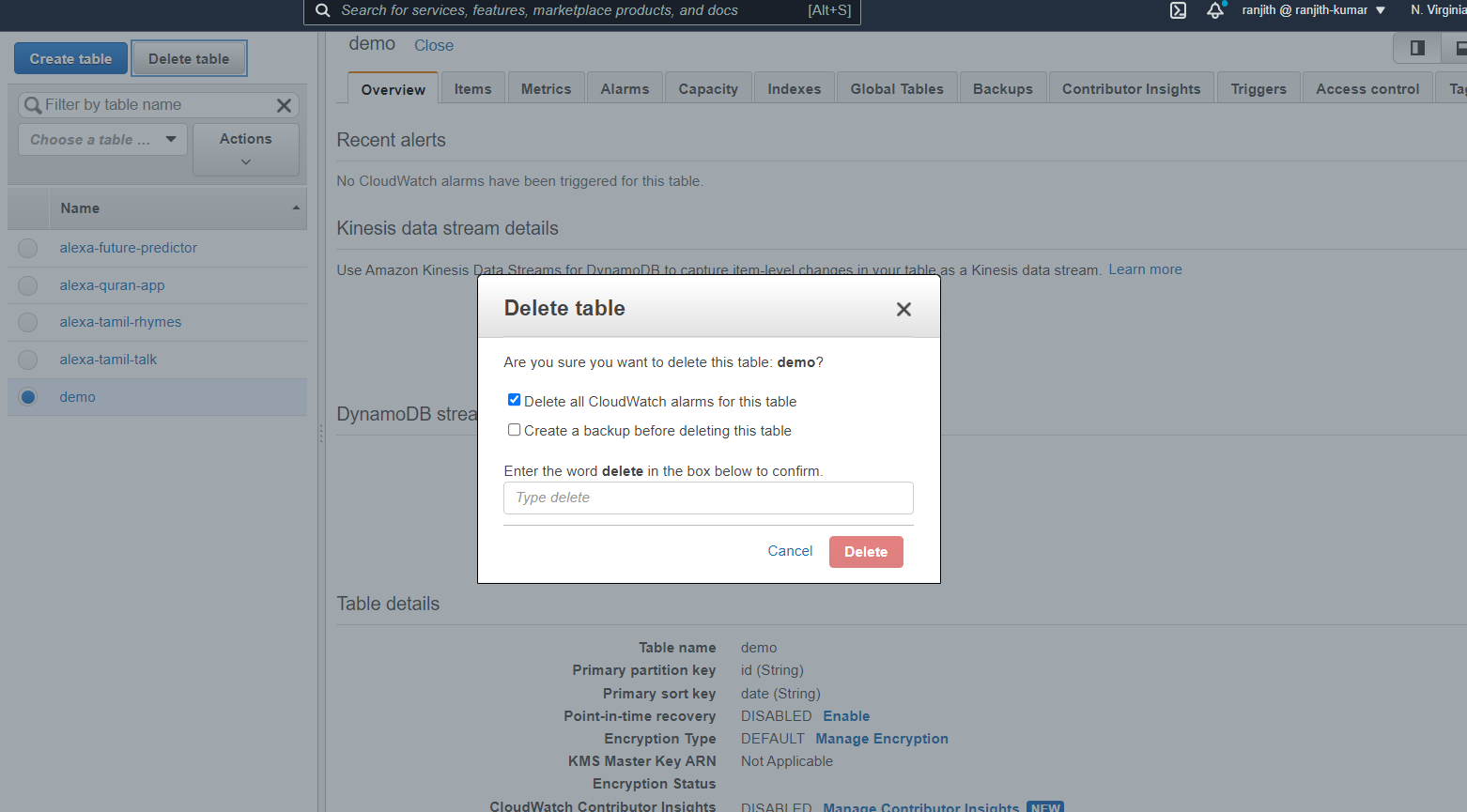
Now if you want to delete it, click on the delete table as shown below, enter delete in the text box and click Delete.
Conclusion
Amazon DynamoDB scales massively and it has proven records of it. I will always go for Amazon DynamoDB whenever I get a chance to work on NoSQL databases.
Happy Programming!!
4 thoughts on “What is Amazon DynamoDB? How to get started?”